

Hình ảnh của Tác giả
# Giới thiệu
Hầu hết những người sử dụng trợ lý mã hóa trí tuệ nhân tạo (AI) ngày nay đều dựa vào các công cụ dựa trên đám mây như Claude Code, GitHub Copilot, Cursor và các công cụ khác. Chúng mạnh mẽ, không nghi ngờ gì. Nhưng có một đánh đổi lớn ẩn mình ngay trước mắt: mã của bạn phải được gửi đến máy chủ của người khác để các công cụ này hoạt động.
Điều đó có nghĩa là mọi hàm, mọi khóa giao diện lập trình ứng dụng (API), mọi lựa chọn kiến trúc nội bộ đều đang được truyền đến Anthropic, OpenAI hoặc một nhà cung cấp khác trước khi bạn nhận được câu trả lời. Và ngay cả khi họ cam kết về quyền riêng tư, nhiều nhóm đơn giản là không thể chấp nhận rủi ro đó. Đặc biệt nếu bạn đang làm việc với:
- Cơ sở mã độc quyền hoặc bảo mật
- Hệ thống khách hàng doanh nghiệp
- Tải công việc nghiên cứu hoặc chính phủ
- Bất cứ điều gì theo thỏa thuận bảo mật (NDA)
Đây là lúc các mô hình mã hóa mã nguồn mở, chạy cục bộ thay đổi cuộc chơi.
Chạy mô hình AI của riêng bạn trên máy tính cục bộ mang lại cho bạn quyền kiểm soát, quyền riêng tư và bảo mật. Không có mã nào rời khỏi máy của bạn. Không có nhật ký bên ngoài. Không có “hãy tin chúng tôi.” Và hơn thế nữa, nếu bạn đã có phần cứng đủ mạnh, bạn có thể tiết kiệm hàng nghìn đô la chi phí API và đăng ký.
Trong bài viết này, chúng ta sẽ xem xét bảy mô hình mã hóa AI mã nguồn mở đạt điểm cao nhất trong các bài kiểm tra hiệu suất mã hóa và đang nhanh chóng trở thành lựa chọn thay thế thực sự cho các công cụ độc quyền.
Nếu bạn muốn xem phiên bản ngắn gọn, hãy cuộn xuống cuối để xem bảng so sánh nhanh của cả bảy mô hình.
# 1. Kimi-K2-Thinking By Moonshot AI
Kimi-K2-Thinking, được phát triển bởi Moonshot AI, là một mô hình tư duy mã nguồn mở tiên tiến được thiết kế như một tác nhân sử dụng công cụ, có khả năng suy luận từng bước trong khi tự động gọi các hàm và dịch vụ. Nó duy trì khả năng thực hiện tác vụ dài hạn ổn định qua 200 đến 300 lệnh gọi công cụ liên tiếp — một cải tiến đáng kể so với mức trôi lệch 30 đến 50 bước thường thấy ở các hệ thống trước đây. Điều này cho phép các quy trình làm việc tự động trong nghiên cứu, mã hóa và viết lách.
Về mặt kiến trúc, K2 Thinking có một mô hình với 1 nghìn tỷ tham số, trong đó 32 tỷ là tham số hoạt động. Nó bao gồm 384 chuyên gia (với 8 chuyên gia được chọn cho mỗi token và 1 chuyên gia dùng chung), 61 lớp (với 1 lớp dày đặc), và 7.168 chiều chú ý với 64 đầu. Nó sử dụng cơ chế chú ý MLA và kích hoạt SwiGLU. Mô hình hỗ trợ cửa sổ ngữ cảnh 256.000 token và có vốn từ vựng 160.000. Đây là một mô hình INT4 gốc sử dụng kỹ thuật huấn luyện nhận biết lượng tử hóa sau huấn luyện (QAT), mang lại tốc độ tăng khoảng 2 lần trong chế độ độ trễ thấp, đồng thời giảm mức sử dụng bộ nhớ GPU.
Hình ảnh của Tác giả
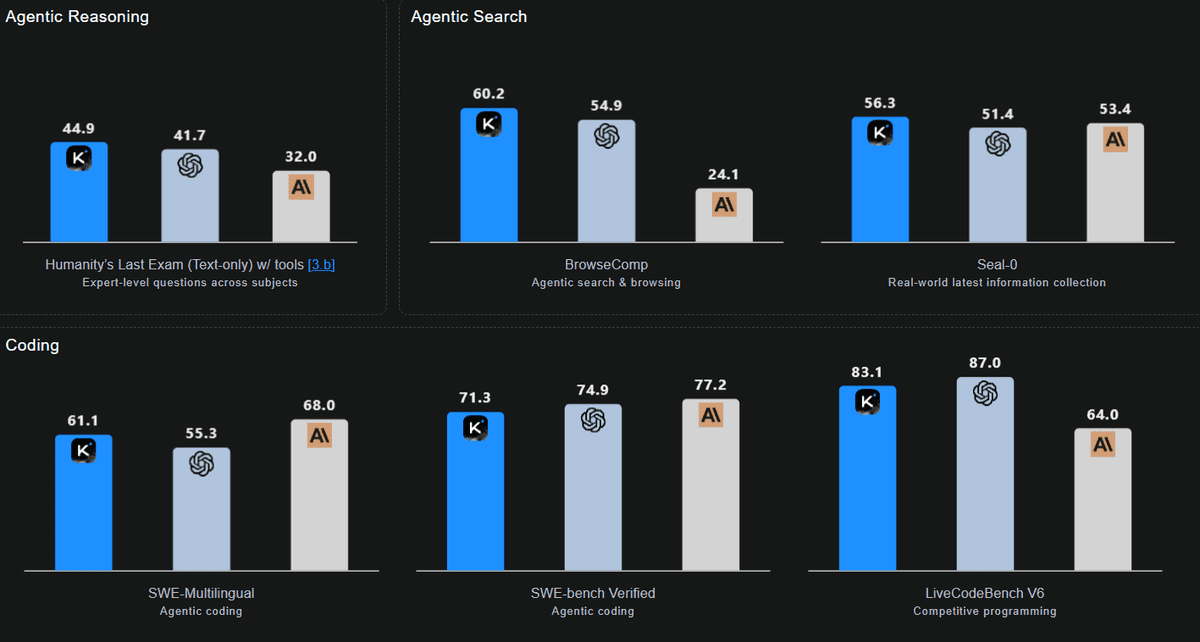
Trong các bài kiểm tra hiệu năng, K2 Thinking đạt được kết quả ấn tượng, đặc biệt trong các lĩnh vực mà suy luận dài hạn và sử dụng công cụ là rất quan trọng. Hiệu suất mã hóa của nó cân bằng tốt, với các điểm số như SWE-bench Verified đạt 71.3, Multi-SWE đạt 41.9, SciCode đạt 44.8, và Terminal-Bench đạt 47.1. Hiệu suất nổi bật của nó thể hiện rõ trong LiveCodeBench V6, nơi nó đạt 83.1 điểm, cho thấy những điểm mạnh đặc biệt trong các quy trình làm việc đa ngôn ngữ và dựa trên tác nhân.
# 2. MiniMax‑M2 By MiniMaxAI
MiniMax-M2 định nghĩa lại hiệu quả cho các quy trình làm việc dựa trên tác nhân. Đây là một mô hình Mixture of Experts (MoE) nhỏ gọn, nhanh chóng và hiệu quả về chi phí, với tổng cộng 230 tỷ tham số, trong đó chỉ có 10 tỷ được kích hoạt cho mỗi token. Bằng cách định tuyến các chuyên gia phù hợp nhất, MiniMax-M2 đạt được hiệu suất sử dụng công cụ từ đầu đến cuối thường thấy ở các mô hình lớn hơn, đồng thời giảm độ trễ, chi phí và mức sử dụng bộ nhớ. Điều này làm cho nó trở nên lý tưởng cho các tác nhân tương tác và lấy mẫu theo lô.
Được thiết kế cho các tác vụ mã hóa và tác nhân cao cấp mà không ảnh hưởng đến trí thông minh tổng thể, nó tập trung vào các vòng lặp lập kế hoạch → thực hiện → xác minh. Các vòng lặp này vẫn phản hồi nhanh chóng nhờ dấu chân kích hoạt 10 tỷ tham số.
Hình ảnh của Tác giả
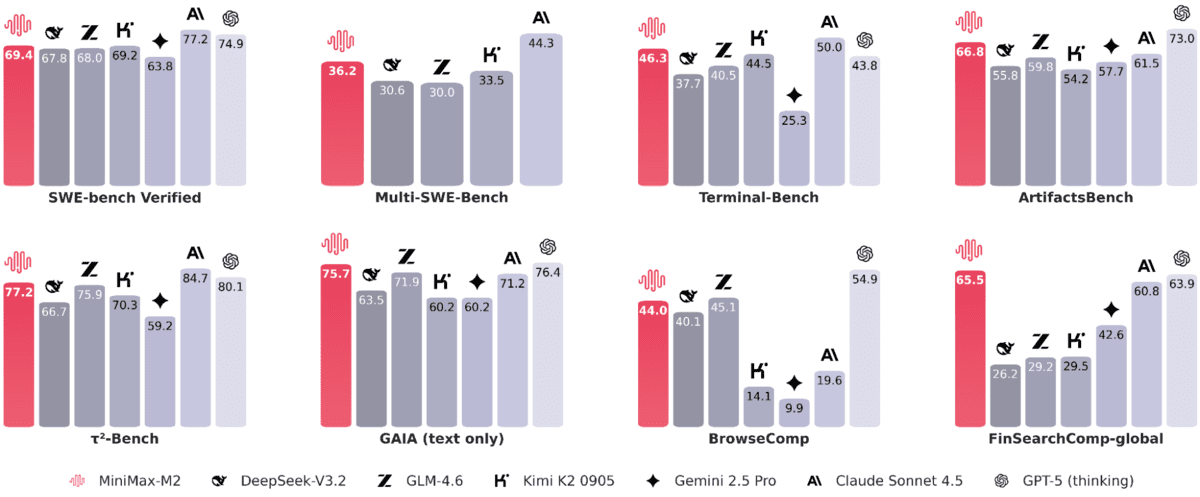
Trong các bài kiểm tra hiệu năng mã hóa và tác nhân thực tế, các kết quả được báo cáo cho thấy hiệu quả thực tiễn mạnh mẽ: SWE-bench đạt 69.4, Multi-SWE-Bench 36.2, SWE-bench Multilingual 56.5, Terminal-Bench 46.3, và ArtifactsBench 66.8. Đối với các tác nhân web và nghiên cứu, điểm số như sau: BrowseComp 44 (với điểm 48.5 bằng tiếng Trung), GAIA (văn bản) 75.7, xbench-DeepSearch 72, τ²-Bench 77.2, HLE (với công cụ) 31.8, và FinSearchComp-global 65.5.
# 3. GPT‑OSS‑120B By OpenAI
GPT-OSS-120b là một mô hình MoE mã nguồn mở được thiết kế để sử dụng trong sản xuất cho các tác vụ tổng quát, yêu cầu khả năng suy luận cao. Nó được tối ưu hóa để chạy trên một GPU 80GB duy nhất và có tổng cộng 117 tỷ tham số, với 5.1 tỷ tham số hoạt động cho mỗi token.
Các khả năng chính của GPT-OSS-120b bao gồm các mức độ nỗ lực suy luận có thể cấu hình (thấp, trung bình, cao), quyền truy cập chuỗi suy nghĩ đầy đủ để gỡ lỗi (không dành cho người dùng cuối), các công cụ tác nhân gốc như gọi hàm, duyệt web, tích hợp Python và đầu ra có cấu trúc, cùng với hỗ trợ tinh chỉnh đầy đủ. Ngoài ra, một mô hình đi kèm nhỏ hơn, GPT-OSS-120b, cũng có sẵn cho những người dùng yêu cầu độ trễ thấp hơn và các ứng dụng cục bộ/chuyên biệt được tùy chỉnh.
Hình ảnh của Tác giả
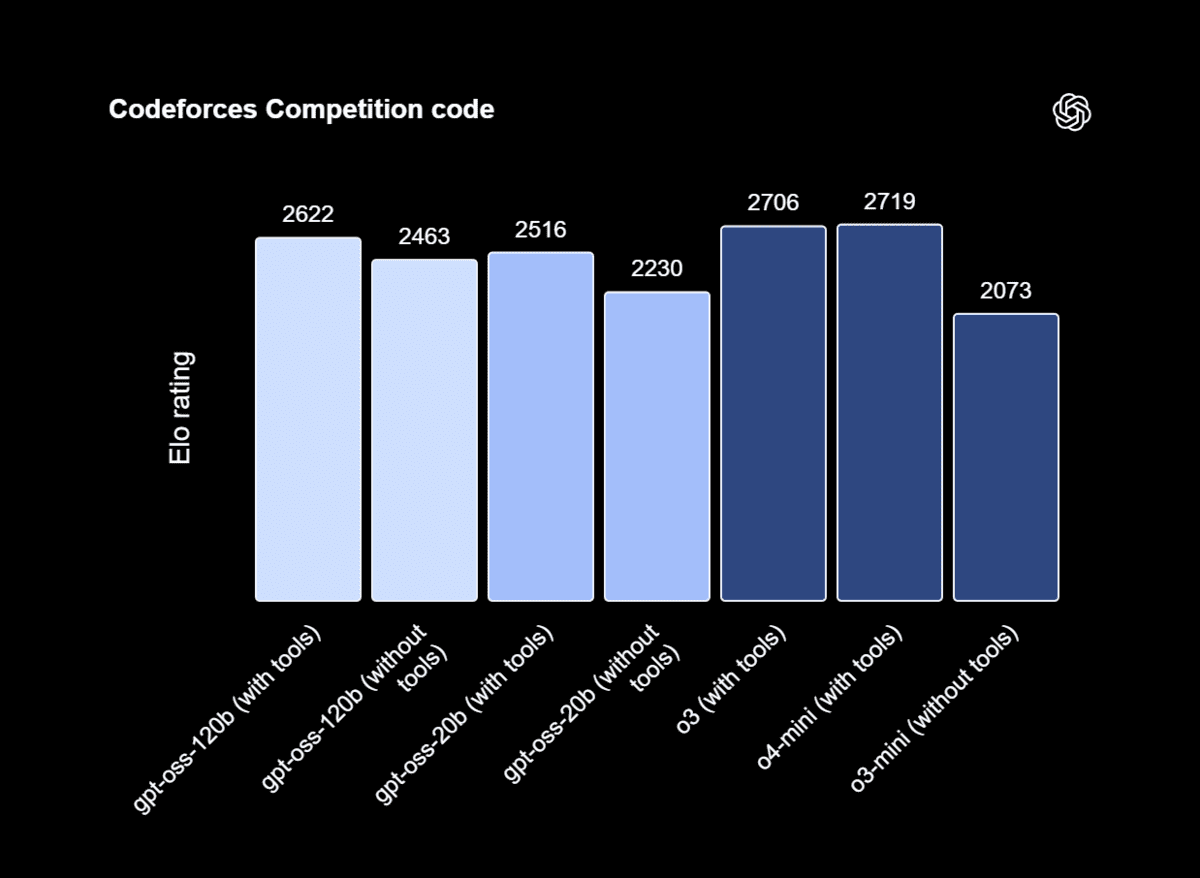
Trong các bài kiểm tra hiệu năng bên ngoài, GPT-OSS-120b xếp thứ ba trong số các mô hình trên Artificial Analysis Intelligence Index. Nó thể hiện một trong những hiệu suất và tốc độ tốt nhất so với kích thước của nó, dựa trên các so sánh đa mô hình về chất lượng, tốc độ đầu ra và độ trễ của Artificial Analysis.
GPT-OSS-120b vượt trội hơn o3-mini và sánh ngang hoặc vượt qua khả năng của o4-mini trong các lĩnh vực như mã hóa thi đấu (Codeforces), giải quyết vấn đề tổng quát (MMLU, HLE), và sử dụng công cụ (TauBench). Hơn nữa, nó vượt trội hơn o4-mini trong các đánh giá sức khỏe (HealthBench) và toán học thi đấu (AIME 2024 và 2025).
# 4. DeepSeek‑V3.2‑Exp By DeepSeek AI
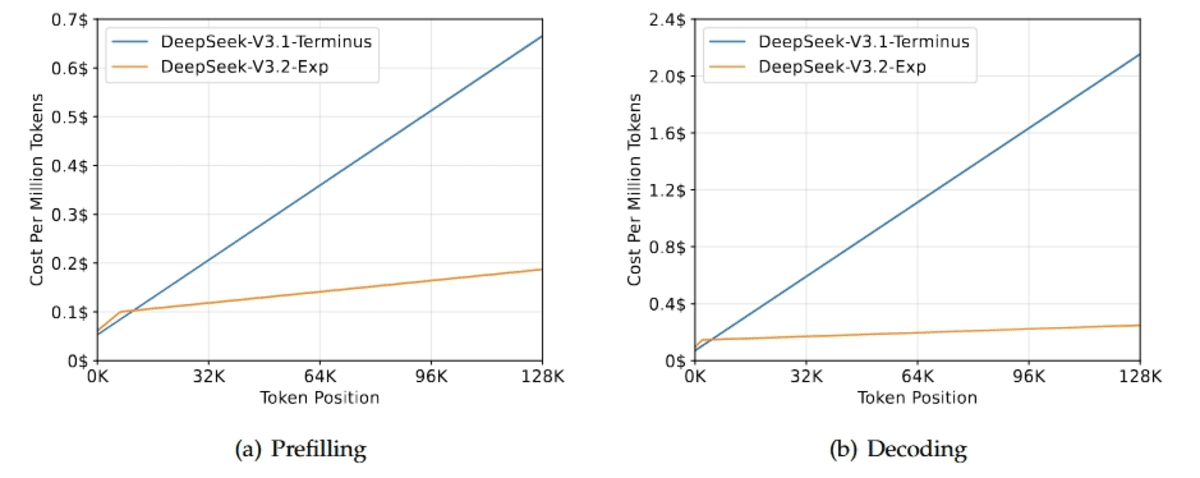
DeepSeek-V3.2-Exp là một bước trung gian thử nghiệm hướng tới thế hệ tiếp theo của kiến trúc của DeepSeek AI. Nó được xây dựng dựa trên V3.1-Terminus và giới thiệu DeepSeek Sparse Attention (DSA), một cơ chế chú ý thưa thớt chi tiết được thiết kế để tăng cường hiệu quả huấn luyện và suy luận trong các kịch bản ngữ cảnh dài.
Trọng tâm chính của bản phát hành này là xác thực những cải thiện về hiệu quả cho các chuỗi dài hơn trong khi vẫn duy trì hành vi mô hình ổn định. Để phân lập tác động của DSA, các cấu hình huấn luyện đã được cố ý điều chỉnh theo các cấu hình của V3.1. Kết quả cho thấy chất lượng đầu ra gần như không thay đổi.
Hình ảnh của Tác giả
Trên các điểm chuẩn công khai, V3.2-Exp hoạt động tương tự như V3.1-Terminus, với những thay đổi nhỏ về hiệu suất: nó đạt 85.0 điểm trên MMLU-Pro, đạt gần mức tương đương trên LiveCodeBench với khoảng 74 điểm, cho thấy sự khác biệt nhỏ trên GPQA (79.9 so với 80.7), và HLE (19.8 so với 21.7). Ngoài ra, có những cải thiện trên AIME 2025 (89.3 so với 88.4) và Codeforces (2121 so với 2046).
# 5. GLM‑4.6 By Z.ai
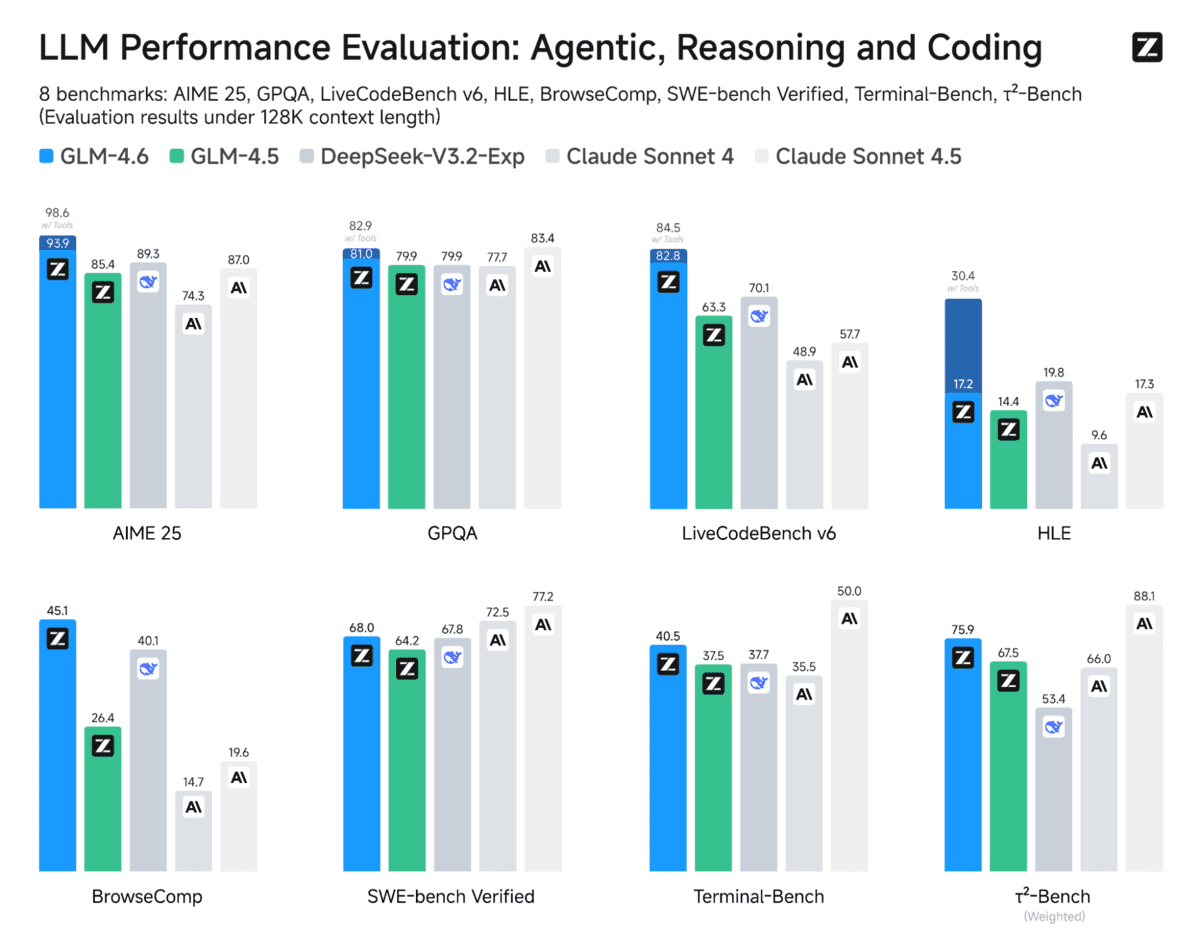
So với GLM‑4.5, GLM‑4.6 mở rộng cửa sổ ngữ cảnh từ 128K lên 200K token. Sự cải tiến này cho phép thực hiện các quy trình làm việc phức tạp hơn và dài hạn hơn mà không bị mất dấu thông tin.
GLM‑4.6 cũng mang lại hiệu suất mã hóa vượt trội, đạt điểm cao hơn trong các bài kiểm tra hiệu năng mã và mang lại kết quả thực tế mạnh mẽ hơn trong các công cụ như Claude Code, Cline, Roo Code và Kilo Code, bao gồm cả khả năng tạo giao diện người dùng tinh vi hơn.
Hình ảnh của Tác giả
Ngoài ra, GLM‑4.6 giới thiệu các khả năng suy luận tiên tiến với việc sử dụng công cụ trong quá trình suy luận, giúp tăng cường hiệu suất tổng thể của nó. Phiên bản này có các tác nhân mạnh mẽ hơn với khả năng sử dụng công cụ và hiệu suất tác nhân tìm kiếm được cải thiện, cùng với sự tích hợp chặt chẽ hơn trong các khung tác nhân.
Trên tám điểm chuẩn công khai bao gồm tác nhân, suy luận và mã hóa, GLM‑4.6 cho thấy những cải tiến rõ rệt so với GLM‑4.5 và duy trì lợi thế cạnh tranh so với các mô hình như DeepSeek‑V3.1‑Terminus và Claude Sonnet 4.
# 6. Qwen3‑235B‑A22B‑Instruct‑2507 By Alibaba Cloud
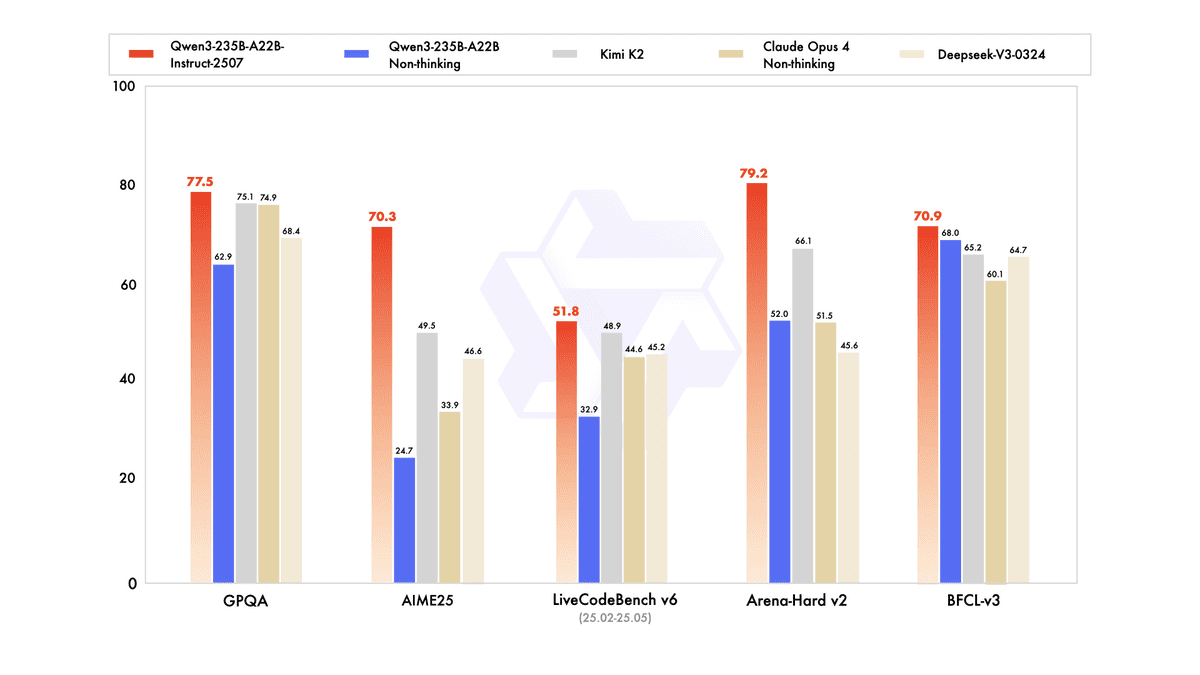
Qwen3-235B-A22B-Instruct-2507 là phiên bản không có khả năng tư duy của mô hình chủ lực của Alibaba Cloud, được thiết kế để ứng dụng thực tế mà không tiết lộ quá trình suy luận của nó. Nó cung cấp những nâng cấp đáng kể về khả năng tổng quát, bao gồm tuân thủ hướng dẫn, suy luận logic, toán học, khoa học, mã hóa và sử dụng công cụ. Ngoài ra, nó đã đạt được những tiến bộ đáng kể về kiến thức đuôi dài trên nhiều ngôn ngữ và thể hiện sự phù hợp tốt hơn với sở thích của người dùng đối với các tác vụ chủ quan và mở.
Là một mô hình không có khả năng tư duy, mục tiêu chính của nó là tạo ra câu trả lời trực tiếp thay vì cung cấp các dấu vết suy luận, tập trung vào tính hữu ích và văn bản chất lượng cao cho các quy trình làm việc hàng ngày.
Hình ảnh của Tác giả
Trong các đánh giá công khai liên quan đến tác nhân, suy luận và mã hóa, nó đã cho thấy những cải tiến rõ rệt so với các bản phát hành trước và duy trì lợi thế cạnh tranh so với các mô hình mã nguồn mở và độc quyền hàng đầu (ví dụ: Kimi-K2, DeepSeek-V3-0324 và Claude-Opus4-Non-thinking), như được ghi nhận bởi các báo cáo của bên thứ ba.
# 7. Apriel‑1.5‑15B‑Thinker By ServiceNow‑AI
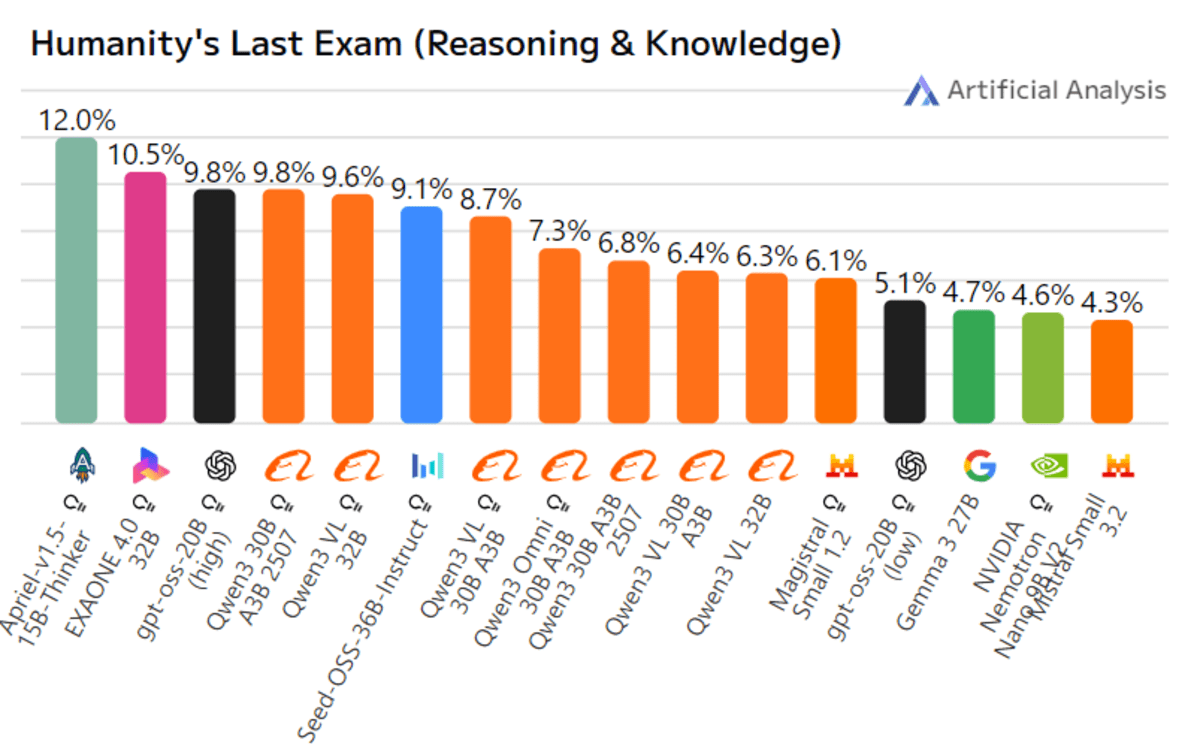
Apriel-1.5-15b-Thinker là mô hình suy luận đa phương thức thuộc dòng mô hình ngôn ngữ nhỏ (SLM) Apriel của ServiceNow AI. Nó giới thiệu khả năng suy luận hình ảnh bên cạnh mô hình văn bản trước đây, nhấn mạnh một chế độ huấn luyện trung gian mạnh mẽ bao gồm việc huấn luyện trước liên tục rộng rãi trên cả văn bản và hình ảnh, sau đó là tinh chỉnh có giám sát (SFT) chỉ với văn bản, không có SFT hình ảnh hoặc học tăng cường (RL). Mặc dù có kích thước nhỏ gọn 15 tỷ tham số, cho phép nó chạy trên một GPU duy nhất, nó tự hào có độ dài ngữ cảnh được báo cáo là khoảng 131.000 token. Mô hình này hướng tới hiệu suất và hiệu quả tương đương với các mô hình lớn hơn nhiều, khoảng mười lần kích thước của nó, đặc biệt trong các tác vụ suy luận.
Hình ảnh của Tác giả
Trong các điểm chuẩn công khai, Apriel-1.5-15B-Thinker đạt 52 điểm trên Artificial Analysis Intelligence Index, giúp nó cạnh tranh với các mô hình như DeepSeek-R1-0528 và Gemini-Flash. Nó được cho là có kích thước chỉ bằng một phần mười so với bất kỳ mô hình nào đạt điểm trên 50. Ngoài ra, nó thể hiện hiệu suất mạnh mẽ như một tác nhân doanh nghiệp, đạt 68 điểm trên Tau2 Bench Telecom và 62 điểm trên IFBench.
# Bảng Tóm tắt
Dưới đây là bảng tóm tắt các mô hình mã nguồn mở cho từng trường hợp sử dụng cụ thể của bạn:
| Mô hình | Kích thước / Ngữ cảnh | Điểm mạnh chính | Phù hợp nhất cho |
|---|---|---|---|
| Kimi-K2-Thinking (MoonshotAI) |
1T / 32B active, 256K ctx | Sử dụng công cụ dài hạn ổn định (~200–300 lệnh gọi); mã hóa đa ngôn ngữ & dựa trên tác nhân mạnh mẽ | Các tác nhân nghiên cứu/mã hóa tự động cần lập kế hoạch liên tục |
| MiniMax-M2 (MiniMaxAI) |
230B / 10B active, 128k ctx | Hiệu quả cao + độ trễ thấp cho các vòng lặp lập kế hoạch→thực hiện→xác minh | Các tác nhân sản xuất có khả năng mở rộng, nơi chi phí + tốc độ là quan trọng |
| GPT-OSS-120B (OpenAI) |
117B / 5.1B active, 128k ctx | Suy luận tổng quát cao với các công cụ gốc; hỗ trợ tinh chỉnh đầy đủ | Triển khai cho doanh nghiệp/riêng tư, mã hóa thi đấu, sử dụng công cụ đáng tin cậy |
| DeepSeek-V3.2-Exp | 671B / 37B active, 128K ctx | DeepSeek Sparse Attention (DSA), suy luận ngữ cảnh dài hiệu quả | Các quy trình phát triển/nghiên cứu cần hiệu quả tài liệu dài |
| GLM-4.6 (Z.ai) |
355B / 32B active, 200K ctx | Mã hóa + suy luận mạnh mẽ; cải thiện việc sử dụng công cụ trong quá trình suy luận | Đồng tác giả mã, khung tác nhân, quy trình làm việc kiểu Claude Code |
| Qwen3-235B (Alibaba Cloud) |
235B, 256K ctx | Câu trả lời trực tiếp chất lượng cao; đa ngôn ngữ; sử dụng công cụ mà không cần đầu ra chuỗi suy nghĩ (CoT) | Tạo mã & tái cấu trúc mã quy mô lớn |
| Apriel-1.5-15B-Thinker (ServiceNow) |
15B, ~131K ctx | Suy luận đa phương thức nhỏ gọn (văn bản+hình ảnh) cho doanh nghiệp | Các tác nhân trên thiết bị/đám mây riêng, tự động hóa DevOps |
Abid Ali Awan (@1abidaliawan) là một chuyên gia khoa học dữ liệu được chứng nhận, người yêu thích xây dựng các mô hình học máy. Hiện tại, anh ấy đang tập trung vào việc tạo nội dung và viết các blog kỹ thuật về công nghệ học máy và khoa học dữ liệu. Abid có bằng Thạc sĩ quản lý công nghệ và bằng Cử nhân kỹ thuật viễn thông. Tầm nhìn của anh ấy là xây dựng một sản phẩm AI sử dụng mạng thần kinh đồ thị cho những sinh viên đang gặp khó khăn về sức khỏe tâm thần.


