
Samsung đang vượt qua những hạn chế của các tiêu chuẩn hiện có để đánh giá tốt hơn năng suất thực tế của các mô hình AI trong môi trường doanh nghiệp. Hệ thống mới, được phát triển bởi Samsung Research và có tên là TRUEBench, nhằm mục đích giải quyết sự chênh lệch ngày càng tăng giữa hiệu suất AI lý thuyết và tiện ích thực tế của nó tại nơi làm việc.
Khi các doanh nghiệp trên toàn thế giới đẩy nhanh việc áp dụng các mô hình ngôn ngữ lớn (LLM) để cải thiện hoạt động của mình, một thách thức đã xuất hiện: làm thế nào để đánh giá chính xác hiệu quả của chúng. Nhiều tiêu chuẩn hiện có tập trung vào các bài kiểm tra kiến thức học thuật hoặc tổng quát, thường giới hạn ở tiếng Anh và các định dạng hỏi đáp đơn giản. Điều này đã tạo ra một khoảng trống khiến các doanh nghiệp không có phương pháp đáng tin cậy để đánh giá cách một mô hình AI sẽ hoạt động trên các tác vụ kinh doanh phức tạp, đa ngôn ngữ và giàu ngữ cảnh.
TRUEBench của Samsung, viết tắt của Trustworthy Real-world Usage Evaluation Benchmark (Tiêu chuẩn Đánh giá Sử dụng Thực tế Đáng tin cậy), đã được phát triển để lấp đầy khoảng trống này. Nó cung cấp một bộ công cụ đo lường toàn diện để đánh giá các LLM dựa trên các kịch bản và nhiệm vụ liên quan trực tiếp đến môi trường doanh nghiệp thực tế. Tiêu chuẩn này dựa trên việc Samsung đã sử dụng rộng rãi các mô hình AI trong nội bộ doanh nghiệp của mình, đảm bảo rằng các tiêu chí đánh giá được xây dựng dựa trên các yêu cầu công việc thực tế.
Khung đánh giá này đánh giá các chức năng doanh nghiệp phổ biến như tạo nội dung, phân tích dữ liệu, tóm tắt tài liệu dài và dịch tài liệu. Chúng được chia thành 10 danh mục riêng biệt và 46 danh mục phụ, cung cấp cái nhìn chi tiết về khả năng năng suất của AI.
“Samsung Research mang đến chuyên môn sâu rộng và lợi thế cạnh tranh thông qua kinh nghiệm AI thực tế của mình,” Ông Paul (Kyungwhoon) Cheun, CTO của Bộ phận DX tại Samsung Electronics và Trưởng bộ phận Samsung Research cho biết. “Chúng tôi kỳ vọng TRUEBench sẽ thiết lập các tiêu chuẩn đánh giá về năng suất.”
Để giải quyết những hạn chế của các tiêu chuẩn cũ hơn, TRUEBench được xây dựng trên nền tảng gồm 2.485 bộ thử nghiệm đa dạng trải rộng trên 12 ngôn ngữ khác nhau và hỗ trợ các kịch bản đa ngôn ngữ. Phương pháp đa ngôn ngữ này rất quan trọng đối với các tập đoàn toàn cầu, nơi thông tin luân chuyển giữa các khu vực khác nhau. Các tài liệu thử nghiệm tự chúng phản ánh sự đa dạng của các yêu cầu tại nơi làm việc, từ những hướng dẫn ngắn gọn chỉ tám ký tự đến phân tích phức tạp các tài liệu dài hơn 20.000 ký tự.
Samsung nhận ra rằng trong bối cảnh kinh doanh thực tế, ý định đầy đủ của người dùng không phải lúc nào cũng được nêu rõ ràng trong lời nhắc ban đầu. Do đó, tiêu chuẩn này được thiết kế để đánh giá khả năng của mô hình AI trong việc hiểu và đáp ứng những nhu cầu doanh nghiệp ngầm này, vượt ra ngoài độ chính xác đơn thuần để đo lường mức độ hữu ích và mức độ liên quan một cách tinh tế hơn.
Để đạt được điều này, Samsung Research đã phát triển một quy trình hợp tác độc đáo giữa các chuyên gia con người và AI để tạo ra các tiêu chí chấm điểm năng suất. Ban đầu, người chú thích thiết lập các tiêu chuẩn đánh giá cho một nhiệm vụ nhất định. Sau đó, một AI xem xét các tiêu chuẩn này, kiểm tra các lỗi tiềm ẩn, mâu thuẫn nội bộ hoặc các ràng buộc không cần thiết có thể không phản ánh kỳ vọng thực tế của người dùng. Theo phản hồi của AI, những người chú thích sẽ tinh chỉnh các tiêu chí. Vòng lặp lặp lại này đảm bảo các tiêu chuẩn đánh giá cuối cùng chính xác và phản ánh một kết quả chất lượng cao.
Quy trình được xác minh chéo này cung cấp một hệ thống đánh giá tự động chấm điểm hiệu suất của các LLM. Bằng cách sử dụng AI để áp dụng các tiêu chí đã được tinh chỉnh này, hệ thống giảm thiểu sự thiên vị chủ quan có thể xảy ra khi chỉ có con người chấm điểm, đảm bảo tính nhất quán và độ tin cậy trên tất cả các bài kiểm tra. TRUEBench cũng áp dụng một mô hình chấm điểm nghiêm ngặt, trong đó một mô hình AI phải đáp ứng mọi điều kiện liên quan đến một bài kiểm tra để nhận được điểm đạt. Cách tiếp cận tất cả hoặc không có gì này đối với các điều kiện riêng lẻ cho phép đánh giá chi tiết và chính xác hơn về hiệu suất của các mô hình AI trên các tác vụ doanh nghiệp khác nhau.
Để tăng cường tính minh bạch và khuyến khích việc áp dụng rộng rãi hơn, Samsung đã công bố công khai các mẫu dữ liệu và bảng xếp hạng của TRUEBench trên nền tảng mã nguồn mở toàn cầu Hugging Face. Điều này cho phép các nhà phát triển, nhà nghiên cứu và doanh nghiệp trực tiếp so sánh hiệu suất năng suất của tối đa năm mô hình AI khác nhau cùng lúc. Nền tảng này cung cấp một cái nhìn tổng quan rõ ràng, nhanh chóng về cách các AI khác nhau so sánh với nhau trong các tác vụ thực tế.
Tại thời điểm viết bài, đây là 20 mô hình hàng đầu theo xếp hạng tổng thể dựa trên tiêu chuẩn AI của Samsung:
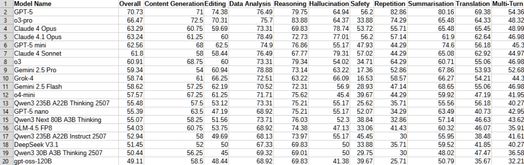
Dữ liệu đầy đủ được công bố cũng bao gồm độ dài trung bình của các phản hồi do AI tạo ra. Điều này cho phép so sánh đồng thời không chỉ hiệu suất mà còn cả hiệu quả, một yếu tố quan trọng đối với các doanh nghiệp khi cân nhắc chi phí vận hành và tốc độ.
Với việc ra mắt TRUEBench, Samsung không chỉ đơn thuần phát hành một công cụ khác mà còn hướng tới việc thay đổi cách ngành công nghiệp nhìn nhận về hiệu suất AI. Bằng cách chuyển trọng tâm từ kiến thức trừu tượng sang năng suất hữu hình, tiêu chuẩn của Samsung có thể đóng vai trò quan trọng trong việc giúp các tổ chức đưa ra quyết định tốt hơn về việc tích hợp mô hình AI doanh nghiệp nào vào quy trình làm việc của họ và thu hẹp khoảng cách giữa tiềm năng của AI và giá trị đã được chứng minh của nó.


