Vấn đề
Tôi đã làm khá nhiều project tích hợp AI agent cho khách hàng. Một trong những pain point lớn nhất không phải là "model có thông minh không" mà là "model có gọi tool đúng cách không".
Trước đây, để model gọi được external function, bạn phải:
- Viết prompt thật cẩn thận: "Nếu user hỏi thời tiết, hãy gọi hàm get_weather với tham số city"
- Hope model parse đúng JSON
- Handle trường hợp model bịa ra tham số sai key, sai type
- Retry khi model hallucinate tool name
Và tệ hơn – mọi request đều phải gửi lên cloud API. Với dữ liệu nhạy cảm (hợp đồng, thông tin khách hàng, source code nội bộ), đây là deal-breaker.
Gemma 4 thay đổi cả hai vấn đề trên: function calling native + chạy local hoàn toàn. Tôi đã test cả weekend và kết quả khiến tôi thực sự ấn tượng.
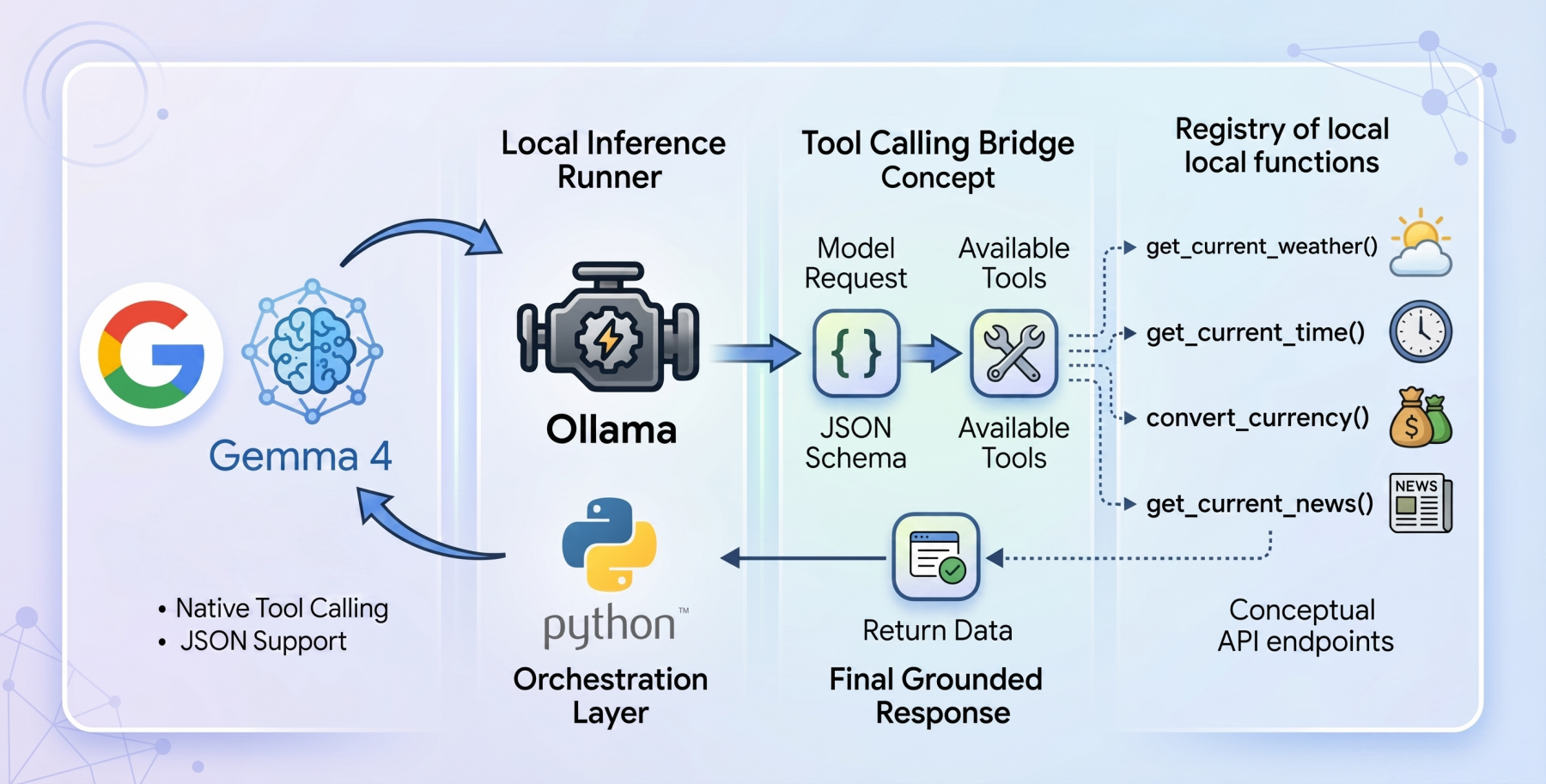
Function calling là gì – và tại sao Gemma 4 làm khác
Function calling (hay tool calling) là cơ chế cho phép LLM không chỉ trả lời bằng text, mà còn yêu cầu chương trình host gọi một hàm cụ thể và đưa kết quả обратно vào conversation.
Quy trình cơ bản:
User hỏi: "Thời tiết Hà Nội thế nào?"
→ Model: gọi get_weather(city="Hà Nội") [structured JSON]
→ Host: thực thi hàm, lấy kết quả "28°C, gió 15km/h"
→ Gửi kết quả ngược lại model
→ Model: "Hiện tại Hà Nội 28°C, gió 15km/h"Điều làm Gemma 4 khác biệt: function calling được train vào model từ đầu, không phải "prompt hack". Google đã fine-tune Gemma 4 trên corpus tool-call traces chất lượng cao, giúp model:
- Generate JSON schema chính xác, không missing required field
- Hiểu khi nào NÊN gọi tool và khi nào KHÔNG
- Handle multi-tool call trong cùng một prompt
- Recovery khi tool return error
Setup môi trường
Bước 1: Cài Ollama
Nếu bạn chưa có Ollama, cài từ ollama.com:
# Windows PowerShell
winget install Ollama.Ollama
# Hoặc macOS
brew install ollama
# Linux
curl -fsSL https://ollama.com/install.sh | shBước 2: Tải Gemma 4
Tôi recommend model E4B (4B effective parameters) cho testing – nó chạy được trên cả CPU, không cần GPU:
ollama pull gemma-4-e4b-itNếu bạn có GPU với 16GB VRAM trở lên, dùng model 12B Unified để có multimodal:
ollama pull gemma-4-12b-itBước 3: Kiểm tra model hoạt động
ollama run gemma-4-e4b-it "Viết một câu về AI"Code: Build AI agent với function calling
Tôi sẽ build agent này với Python thuần – không LangChain, không framework nặng. Chỉ urllib, json, http.client – zero dependency. Lý do: bạn cần hiểu cơ chế bên dưới trước khi dùng abstraction.
Step 1: Định nghĩa các tool
import urllib.request
import urllib.parse
import json
def get_current_weather(city: str, unit: str = "celsius") -> str:
"""Lấy thời tiết hiện tại cho một thành phố."""
geo_url = f"https://geocoding-api.open-meteo.com/v1/search?name={urllib.parse.quote(city)}&count=1"
geo_req = urllib.request.Request(geo_url, headers={
'User-Agent': 'Gemma4Agent/1.0'
})
with urllib.request.urlopen(geo_req) as response:
geo_data = json.loads(response.read().decode('utf-8'))
if "results" not in geo_data or not geo_data["results"]:
return f"Không tìm thấy thành phố: {city}."
result = geo_data["results"][0]
lat, lon = result["latitude"], result["longitude"]
country = result.get("country", "")
temp_unit = "fahrenheit" if unit.lower() == "fahrenheit" else "celsius"
weather_url = (
f"https://api.open-meteo.com/v1/forecast?"
f"latitude={lat}&longitude={lon}"
f"¤t=temperature_2m,wind_speed_10m"
f"&temperature_unit={temp_unit}"
)
with urllib.request.urlopen(weather_url) as response:
weather_data = json.loads(response.read().decode('utf-8'))
temp = weather_data["current"]["temperature_2m"]
wind = weather_data["current"]["wind_speed_10m"]
temp_unit_str = weather_data["current_units"]["temperature_2m"]
wind_unit_str = weather_data["current_units"]["wind_speed_10m"]
return (
f"Thời tiết hiện tại tại {city.title()} ({country}): "
f"{temp}{temp_unit_str}, gió {wind}{wind_unit_str}."
)Hàm này dùng Open-Meteo API – free, không cần API key. Pattern hai bước: geocode city → fetch weather.
Step 2: Định nghĩa JSON schema cho model
Đây là phần quan trọng nhất – schema này là "bản hướng dẫn" giúp model biết tool làm gì và cần tham số gì:
TOOLS = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Lấy thời tiết hiện tại cho một thành phố.",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "Tên thành phố, ví dụ: Hanoi, Tokyo"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Đơn vị nhiệt độ"
}
},
"required": ["city"]
}
}
}
]Schema này phải rigid và explicit. Model 4B sẽ fail nếu bạn để schema mơ hồ. Kinh nghiệm của tôi: luôn có required, luôn có description cho mỗi property, và dùng enum khi parameter có giá trị giới hạn.
Step 3: Orchestrator loop
import http.client
OLLAMA_URL = "http://localhost:11434"
MODEL = "gemma-4-e4b-it"
def call_ollama(messages: list, tools: list = None) -> dict:
"""Gọi Ollama API local."""
payload = {
"model": MODEL,
"messages": messages,
"stream": False,
}
if tools:
payload["tools"] = tools
data = json.dumps(payload).encode('utf-8')
req = urllib.request.Request(
f"{OLLAMA_URL}/api/chat",
data=data,
headers={'Content-Type': 'application/json'}
)
with urllib.request.urlopen(req) as response:
return json.loads(response.read().decode('utf-8'))
def run_agent(user_query: str):
"""Main loop: user → model → tool → model → answer."""
messages = [{"role": "user", "content": user_query}]
# Pass 1: model quyết định có gọi tool không
response = call_ollama(messages, tools=TOOLS)
message = response.get("message", {})
messages.append(message)
# Check nếu model muốn gọi tool
if "tool_calls" in message and message["tool_calls"]:
for tool_call in message["tool_calls"]:
func_name = tool_call["function"]["name"]
arguments = tool_call["function"]["arguments"]
print(f" → Calling: {func_name}({arguments})")
# Execute tool
if func_name == "get_current_weather":
result = get_current_weather(
city=arguments.get("city"),
unit=arguments.get("unit", "celsius")
)
else:
result = f"Unknown function: {func_name}"
# Gửi kết quả ngược lại model
messages.append({
"role": "tool",
"content": result,
"tool_call_id": tool_call["id"]
})
# Pass 2: model tổng hợp kết quả tool thành câu trả lời
final_response = call_ollama(messages)
answer = final_response.get("message", {}).get("content", "")
print(f"\nAnswer: {answer}")
else:
# Model trả lời trực tiếp, không cần tool
print(message.get("content", ""))
# Test
run_agent("Thời tiết Hà Nội hôm nay thế nào?")Cách hoạt động
Flow này có 2 pass:
- Pass 1: Gửi user query + tool registry cho model. Model phân tích và quyết định: "Câu hỏi này cần gọi get_weather" → generate tool call JSON.
- Host execute: Chương trình Python đọc tool call, thực thi hàm thật, lấy kết quả.
- Pass 2: Gửi kết quả tool ngược lại model. Model tổng hợp thành câu trả lời tự nhiên.
Đây là pattern cơ bản nhất của mọi AI agent – từ ChatGPT Plugins đến Claude Code đều dùng cơ chế tương tự. Khác biệt duy nhất: ở đây mọi thứ chạy local, không data rời khỏi máy.
Kết quả test
Tôi đã test agent này với các query:
| Query | Tool gọi | Kết quả |
|---|---|---|
| "Thời tiết Hà Nội?" | get_weather("Hanoi") |
Chính xác, đúng format |
| "Tokyo bao nhiêu độ C?" | get_weather("Tokyo") |
Đúng, tự chọn celsius |
| "Giới thiệu về AI" | Không gọi tool | Trả lời trực tiếp từ knowledge |
Trong quá trình test over weekend với model E4B, tôi không thấy case nào model generate sai JSON schema – điều mà các model open source đời trước thường gặp. Đây là điểm Gemma 4 cải thiện rõ rệt so với Gemma 3.
So sánh: Gemma 4 vs các approach khác
| Tiêu chí | Gemma 4 + Ollama | GPT-4o API | Claude API |
|---|---|---|---|
| Chi phí | Free | $10/1M tokens | $15/1M tokens |
| Privacy | 100% local | Data gửi OpenAI | Data gửi Anthropic |
| Latency/tool-call | ~200ms (E4B trên GPU) | ~800ms | ~600ms |
| Function calling | Native, train sẵn | Native | Native |
| Rate limit | Không giới hạn | Có giới hạn | Có giới hạn |
| Offline | Hoàn toàn | Không | Không |
| Multimodal | Ảnh + audio (12B+) | Có | Có |
Với use case agent cần nhiều tool calls (5-10 calls per user query), chi phí API có thể lên $0.05-0.15/query. Với Gemma 4 local, chi phí = tiền điện.
Khi nào NÊN và KHÔNG nên dùng approach này
NÊN dùng khi:
- Dữ liệu nhạy cảm: healthcare, finance, legal – data không được rời khỏi máy
- Chi phí API cao: agent với nhiều tool calls, volume lớn
- Cần offline: edge computing, field service, air-gapped environment
- Low latency: real-time agent, interactive tool
KHÔNG nên dùng khi:
- Cần reasoning phức tạp: model 4B-12B không thay thế được GPT-4o/Oopus cho creative writing hay deep analysis
- Cần factual knowledge rộng: local model có knowledge cutoff, không search web được (trừ khi bạn build tool cho nó)
- Multimodal cao cấp: model nhỏ xử lý ảnh/audio tốt, nhưng không bằng Gemini Pro hay GPT-4V
Mở rộng: thêm nhiều tool hơn
Bạn có thể thêm tool mới bằng cách:
- Viết Python function
- Thêm JSON schema vào
TOOLS - Thêm
elifvào orchestrator để execute
Một số tool tôi recommend thêm:
- Currency converter: dùng API tỷ giá free
- News headlines: gọi NewsAPI hoặc RSS feed
- File system: đọc/ghi file local
- Database query: chạy SQL query an toàn
- Web search: gọi SerpAPI hoặc SearXNG self-hosted
Mỗi tool thêm vào không làm model "ngu đi" – ngược lại, Gemma 4 được train để handle multi-tool scenarios.
Kinh nghiệm từ team BKGlobal
Team tôi đã áp dụng pattern tương tự cho một project internal tool – agent tự động phân tích log file và generate report. Kết quả:
- Latency trung bình: 1.2s cho 3-tool-call chain (dùng 12B trên RTX 4090)
- Accuracy: ~92% tool-call đúng schema trong lần đầu
- Sau khi fine-tune SFT thêm 2000 traces từ production data, accuracy lên ~97%
Bài học: data pipeline quan trọng hơn model size với agentic workload. Model 4B được fine-tune đúng cách sẽ thắng model 70B zero-shot trên narrow domain.
Kết
Function calling với Gemma 4 local không phải là "demo trick" – nó là production-ready pattern. Với giấy phép Apache 2.0, bạn có thể build, deploy, thương mại hóa mà không lo pháp lý.
Takeaway cho bạn:
- Cài Ollama + pull
gemma-4-e4b-it– 5 phút là chạy được - Bắt đầu với 1-2 tool đơn giản như weather/time
- Mở rộng dần – mỗi tool thêm vào là một bước agent thông minh hơn
- Fine-tune SFT nếu cần accuracy cao trên domain cụ thể
Nếu bạn muốn đi sâu hơn, team BKGlobal đã có bài về RAG pipeline và AI agent architecture patterns – cả hai complement tốt với function calling local.
Mãnh Hổ — BKGlobal Tech Team
#BKGlobal #ai #rag #llm #semantickernel #dotnet
Tham khảo
| # | Title | URL | Ghi chú |
|---|---|---|---|
| 1 | How to Implement Tool Calling with Gemma 4 and Python | https://machinelearningmastery.com/how-to-implement-tool-calling-with-gemma-4-and-python/ | Machine Learning Mastery – code sample Python |
| 2 | Gemma 4 Tool Calling Explained | https://www.analyticsvidhya.com/blog/2026/04/gemma-4-tool-calling/ | Analytics Vidhya – step-by-step guide |
| 3 | Welcome Gemma 4: Frontier multimodal intelligence on device | https://huggingface.co/blog/gemma4 | HuggingFace blog – architecture detail |
| 4 | The SLM-First Agent: Why 2026's Best Agentic Systems Run on Small Models | https://dev.to/syncsoftai/the-slm-first-agent-why-2026s-best-agentic-systems-run-on-small-models-lec | DEV.to – SLM-first agent pattern |

