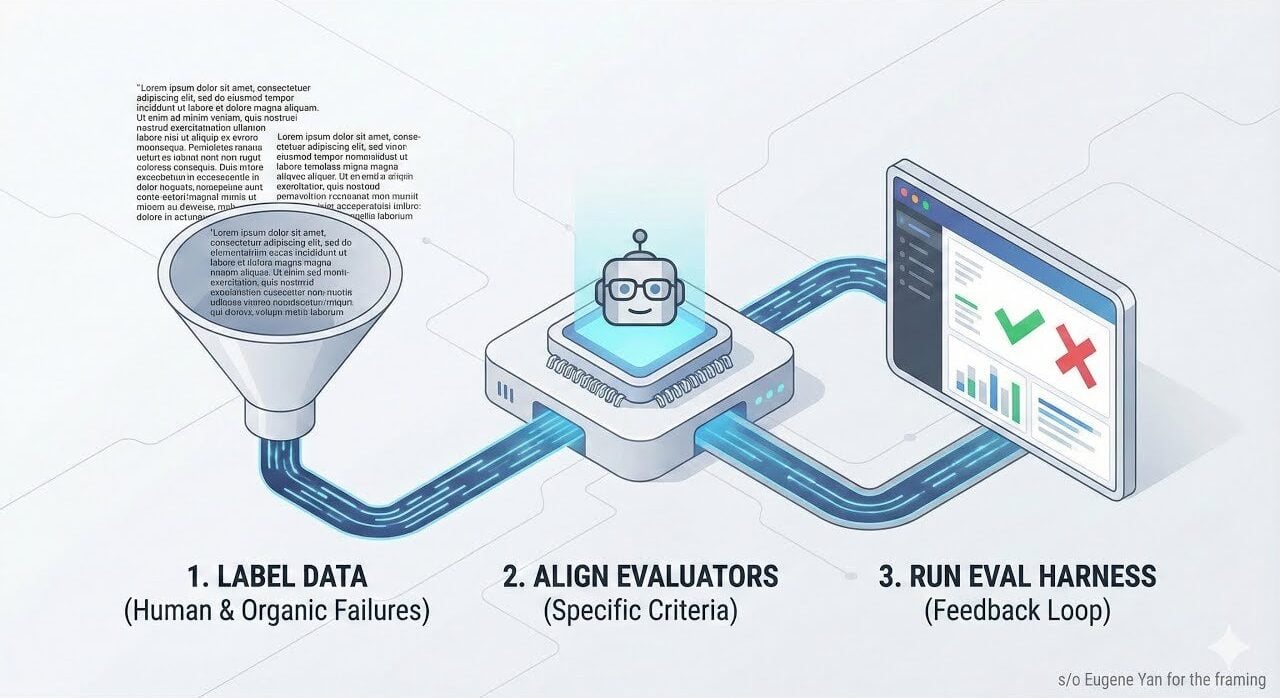
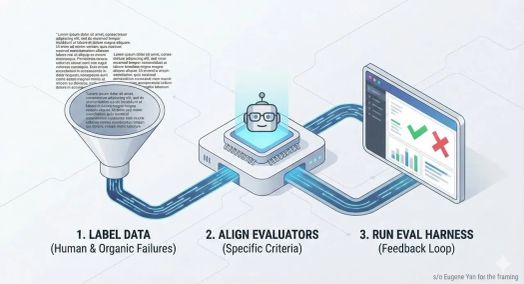
Điều gì sẽ xảy ra nếu sự thành công của ứng dụng AI của bạn chỉ phụ thuộc vào ba bước? Trong một thế giới nơi các mô hình ngôn ngữ lớn (LLM) đang định hình lại các ngành công nghiệp, khả năng đánh giá hiệu suất của chúng một cách hiệu quả trở nên quan trọng hơn bao giờ hết. Tuy nhiên, nhiều nhóm gặp khó khăn trong việc vượt qua các tiêu chuẩn mơ hồ hoặc các phương pháp thử nghiệm chung chung, khiến hệ thống của họ dễ bị không nhất quán và sai lệch. Sự thật là, một quy trình đánh giá có cấu trúc có thể tạo nên sự khác biệt giữa một AI mang lại kết quả đáng tin cậy, thực tế và một AI không đạt được kỳ vọng. Báo cáo này cung cấp một khuôn khổ rõ ràng, có thể hành động để giúp bạn tự tin vượt qua thử thách này.
Trong các phần sau, LangChain sẽ hướng dẫn bạn qua một phương pháp ba bước được thiết kế để hợp lý hóa việc đánh giá các ứng dụng AI. Từ việc tạo ra một bộ dữ liệu có mục đích cụ thể đến việc điều chỉnh các công cụ đánh giá và thực hiện các bài kiểm tra lặp đi lặp lại, mỗi bước đều xây dựng dựa trên bước trước để đảm bảo hệ thống của bạn phát triển với độ chính xác và mục đích. Cho dù bạn đang tinh chỉnh đầu ra để đáp ứng các mục tiêu về phong cách hay khắc phục các lỗ hổng về hiệu suất, quy trình này trang bị cho bạn các công cụ để tinh chỉnh ứng dụng và thích ứng với các yêu cầu thay đổi. Cuối cùng, bạn sẽ không chỉ hiểu cách đánh giá AI một cách hiệu quả mà còn có được những hiểu biết sâu sắc về cách tạo ra các hệ thống năng động như những thách thức mà chúng được xây dựng để giải quyết.
Hướng dẫn đánh giá LLM hiệu quả
Tóm tắt các điểm chính :
- Đánh giá hiệu quả các ứng dụng mô hình ngôn ngữ lớn (LLM) bao gồm một quy trình ba bước có cấu trúc: gắn nhãn dữ liệu, điều chỉnh công cụ đánh giá và thực hiện các bài kiểm tra lặp lại.
- Tạo một bộ dữ liệu có mục đích cụ thể với các tiêu chí gắn nhãn rõ ràng đảm bảo quy trình đánh giá phù hợp với các mục tiêu cụ thể và định nghĩa sự thành công có thể đo lường được cho ứng dụng.
- Điều chỉnh công cụ đánh giá LLM với các tiêu chí đã định giúp tinh chỉnh đầu ra để đáp ứng các kỳ vọng về phong cách, giọng điệu và chức năng, đòi hỏi phải điều chỉnh liên tục khi nhu cầu phát triển.
- Kiểm tra lặp đi lặp lại với một bộ công cụ đánh giá cho phép cải tiến liên tục bằng cách xác định sự không nhất quán, mở rộng tập dữ liệu và tinh chỉnh hiệu suất hệ thống theo thời gian.
- Tùy chỉnh và lặp lại là điều cần thiết để điều chỉnh quy trình đánh giá theo các yêu cầu ứng dụng riêng biệt, đảm bảo kết quả đáng tin cậy và chất lượng cao phù hợp với các yêu cầu thực tế.
Bước 1: Gắn nhãn một bộ dữ liệu nhỏ, được xây dựng có mục đích
Nền tảng của bất kỳ quy trình đánh giá hiệu quả nào bắt đầu bằng việc tạo một bộ dữ liệu phản ánh trường hợp sử dụng cụ thể của bạn. Ví dụ, nếu mục tiêu của bạn là chuyển đổi các bài đăng blog dài thành các tweet ngắn gọn, chuyên nghiệp, bộ dữ liệu của bạn nên bao gồm các ví dụ về cả đầu vào (nội dung dạng dài) và đầu ra mong muốn (các tweet ngắn, được trau chuốt). Gắn nhãn bộ dữ liệu này bằng các tiêu chí nhị phân rõ ràng, chẳng hạn như “đạt” hoặc “không đạt”—để xác định xem đầu ra có đáp ứng kỳ vọng của bạn hay không.
Tại sao bước này lại cần thiết?
- Nó thiết lập một định nghĩa rõ ràng và có thể đo lường được về sự thành công cho ứng dụng của bạn.
- Nó đảm bảo quy trình đánh giá được căn chỉnh trực tiếp với các mục tiêu và yêu cầu riêng của bạn.
- Nó tránh sự phụ thuộc vào các tiêu chuẩn đánh giá chung chung hoặc quá rộng có thể không phù hợp với nhu cầu của bạn.
Ví dụ, nếu việc duy trì giọng điệu chuyên nghiệp là ưu tiên, tiêu chí gắn nhãn của bạn nên phản ánh rõ ràng yêu cầu này. Bằng cách tạo ra các nhãn chính xác và có mục đích, bạn đặt một nền tảng vững chắc cho quy trình đánh giá, đảm bảo các bước tiếp theo tập trung và hiệu quả.
Bước 2: Điều chỉnh công cụ đánh giá LLM
Sau khi gắn nhãn bộ dữ liệu của bạn, bước tiếp theo là điều chỉnh công cụ đánh giá LLM với các tiêu chí đã định của bạn. Điều này liên quan đến việc huấn luyện công cụ đánh giá để nhận biết và ưu tiên các kết quả mà bạn đã vạch ra. Những sự không phù hợp có thể xảy ra ở giai đoạn này, nhưng chúng có thể được khắc phục thông qua việc tinh chỉnh và lặp lại cẩn thận.
Làm thế nào để đạt được sự điều chỉnh?
- Nếu công cụ đánh giá tạo ra các đầu ra có vẻ quá quảng cáo hoặc nhân tạo, hãy điều chỉnh tiêu chí đánh giá để loại bỏ những kết quả đó.
- Nếu đầu ra không đáp ứng các hướng dẫn về phong cách hoặc giọng điệu, hãy tinh chỉnh các thông số của công cụ đánh giá để phù hợp hơn với kỳ vọng của bạn.
Bước này không phải là một nhiệm vụ chỉ thực hiện một lần. Khi những thách thức mới xuất hiện hoặc yêu cầu phát triển, bạn có thể cần xem xét lại và điều chỉnh các tiêu chí của mình. Mục tiêu cuối cùng là đảm bảo công cụ đánh giá liên tục tạo ra các đầu ra đáp ứng tiêu chuẩn của bạn, cho dù điều đó liên quan đến việc tránh cách diễn đạt giống AI, tuân thủ các ưu tiên phong cách cụ thể hay duy trì một giọng điệu nhất định.
Đánh giá sản phẩm (cho ứng dụng AI) trong ba bước đơn giản
Hãy xem các hướng dẫn sâu sắc khác từ bộ sưu tập phong phú của chúng tôi có thể thu hút sự quan tâm của bạn về Các mô hình ngôn ngữ lớn (LLM).
- Tốc độ lưu trữ ảnh hưởng đến hiệu suất mô hình ngôn ngữ lớn như thế nào
- ChatHub AI cho phép bạn chạy các mô hình ngôn ngữ lớn (LLM) song song
- LLM dựa trên Diffusion là gì? Giải thích tốc độ AI của Mercury
- Cách chạy các mô hình ngôn ngữ lớn AI (LLM) trên máy tính xách tay của bạn
- Các mô hình ngôn ngữ lớn như GPT thực sự hoạt động như thế nào?
- Cách chạy các mô hình ngôn ngữ lớn cục bộ với Vast AI
- Triển khai DeepSeek và các mô hình AI lớn cục bộ trên điện thoại của bạn để
- Bỏ ChatGPT, chạy AI riêng tư trên máy tính xách tay của bạn trong 15 phút
- Hiểu tác động của LLM tự tiến hóa đối với AI
Bước 3: Kiểm tra lặp đi lặp lại với một bộ công cụ đánh giá
Bước cuối cùng trong quy trình đánh giá là kiểm tra hệ thống của bạn bằng cách sử dụng một bộ công cụ đánh giá. Điều này liên quan đến việc chạy các lời nhắc qua LLM và đánh giá các đầu ra dựa trên các tiêu chí đã thiết lập của bạn. Mỗi sửa đổi, cho dù đó là một lời nhắc mới, một điều chỉnh mô hình hay một tinh chỉnh tham số, đều phải được kiểm tra để đánh giá tác động của nó đến hiệu suất.
Tại sao kiểm tra lặp lại lại quan trọng?
- Nó cho phép bạn xác định sự không nhất quán hoặc thiếu sót trong các đầu ra của hệ thống và giải quyết chúng kịp thời.
- Nó cung cấp cơ hội để mở rộng bộ dữ liệu của bạn với các ví dụ bổ sung, đặc biệt nếu hệ thống gặp khó khăn với các loại đầu vào cụ thể.
Các vòng phản hồi đóng một vai trò quan trọng trong giai đoạn này. Bằng cách phân tích kết quả của mỗi lần kiểm tra, bạn có thể xác định các lĩnh vực cần cải thiện và thực hiện các điều chỉnh có mục tiêu. Ví dụ, nếu một thay đổi cấu hình dẫn đến đầu ra không nhất quán, bạn có thể tinh chỉnh các lời nhắc hoặc huấn luyện lại công cụ đánh giá để giải quyết vấn đề. Phương pháp lặp lại này đảm bảo hệ thống của bạn phát triển theo thời gian, thích ứng với các yêu cầu mới và cải thiện độ tin cậy tổng thể của nó.
Vai trò của sự lặp lại trong cải tiến liên tục
Đánh giá một ứng dụng LLM không phải là một nỗ lực một lần. Nó đòi hỏi sự lặp lại liên tục để thích ứng với các nhu cầu thay đổi và cải thiện hiệu suất. Khi ứng dụng của bạn phát triển, các bước trước đó, chẳng hạn như gắn nhãn dữ liệu bổ sung hoặc tinh chỉnh công cụ đánh giá, có thể cần được xem xét lại. Quá trình lặp lại này xây dựng sự tự tin vào khả năng hoạt động đáng tin cậy của hệ thống trong các kịch bản thực tế, đa dạng.
Tùy chỉnh: Điều chỉnh quy trình theo nhu cầu của bạn
Mỗi ứng dụng LLM là duy nhất, và quy trình đánh giá nên phản ánh sự độc đáo này. Tùy chỉnh là chìa khóa để đảm bảo hệ thống đáp ứng các mục tiêu cụ thể của bạn. Các công cụ như Langsmith có thể đơn giản hóa quy trình này bằng cách cung cấp các tính năng cho việc gắn nhãn dữ liệu, điều chỉnh công cụ đánh giá và kiểm tra lặp lại. Các công cụ này cho phép bạn điều chỉnh quy trình đánh giá, giúp dễ dàng đạt được các kết quả mong muốn trong khi vẫn duy trì hiệu quả và độ chính xác.
Bằng cách tuân theo phương pháp ba bước có cấu trúc này, gắn nhãn một bộ dữ liệu có mục đích cụ thể, điều chỉnh công cụ đánh giá và thực hiện các bài kiểm tra lặp lại, bạn có thể đánh giá và tinh chỉnh ứng dụng AI của mình một cách có hệ thống. Cách tiếp cận này đảm bảo cải tiến liên tục, cho phép hệ thống của bạn thích ứng với các yêu cầu phát triển và mang lại kết quả đáng tin cậy, chất lượng cao phù hợp với nhu cầu của bạn.
Nguồn ảnh/video: LangChain
Đã phân loại: AI, Tin tức công nghệ, Tin nổi bật
Các ưu đãi mới nhất từ Geeky Gadgets
Tiết lộ: Một số bài viết của chúng tôi có chứa liên kết liên kết (affiliate links). Nếu bạn mua hàng thông qua một trong các liên kết này, Geeky Gadgets có thể kiếm được hoa hồng liên kết. Tìm hiểu về Chính sách tiết lộ của chúng tôi.


